


Now that Serverless September 2020 is coming to an end, we thought it was a good idea to share our knowledge of Functions-as-a-Service and Serverless that we have built up over the past years. In this blog, we will provide insight and introduce techniques that you can use to improve your Azure functions' performance. We will also share how we were able to reduce CosmosDB performance from seconds to milliseconds.
What are Azure functions
Azure functions is the Functions-as-a-Service (FaaS) solution from Azure. You can compare it with AWS Lambda, but we will see a couple of crucial differences in the setup of those services. One key difference is the availability of an app service pricing plan besides the consumption pricing plan.
In the consumption plan, infrastructure resources and provisioning thereof is handled by the Azure platform. Using the dedicated app service plan allows you to pre-provision a fixed set of resources on which the Azure function will run.
This blog will make use of the consumption plan for running functions.
Azure functions consumption plan
As stated before, the consumption plan of Azure functions allows us to offload the responsibility of scaling the solution to the Azure platform. This gives developers the freedom to focus on writing code without worrying about the underlying servers, network, or scaling. Other than making the developers more productive, there is also a benefit on the infrastructure cost. A function in the consumption plan will automatically scale to zero. This also means that your function won't add to your Azure bill when there are no requests to handle. With the consumption plan, you pay for:
- the number of requests that your function handles,
- the amount of time & memory the function consumes to serve the request.
This also means that the performance of your code is not only important for user experience but can impact your Azure bill as well.
The other side of the coin
Scaling down to zero using the consumption plan reduces the cost of the Azure bill. However, there is another price to pay: cold starts.
The benefit of functions using a consumption plan is that the functions can scale to zero. Meaning when there is no traffic to your API, Azure will remove all underlying servers on which your functions are running. Hence, removing any costs for your Azure function. This, however, also results in the need to provision a VM (Virtual Machine) on the fly if a new request comes in after the function was scaled to zero. Only after a VM is provisioned, the actual request is handled. These actions, performed by Azure behind the scenes, take some time called the cold start time.
Other than on a first request, you can also encounter cold starts when the number of requests spikes and Azure needs to provision or start more functions to handle all requests.
Cold starts are a known problem for FaaS solutions, however, Azure is continuously improving cold start time:
- They will keep the VMs running for about 15 minutes even when there is no traffic.
- They will use traffic predictions, starting more VMs than needed at this moment to be able to serve requests in the near future.
- They will improve the actual start-up times of their VMs running the functions.
Next to the improvements from Azure, you can also reduce the cold start time as a developer by keeping your package/artifact size as small as possible. Another great way to improve cold starts is by avoiding them entirely.
- You can keep your functions "warm" (keep on reading for more details)
- You should try to limit the duration of the function invocation as much as possible. If your function code runs fast, many requests can be handled by one VM instance without scaling out, incurring more cold starts.
However, if cold starts are a real problem for your use case, you can also choose the Azure functions premium plan. This plan works with the consumption billing plan and will keep at least one instance of your function running to avoid cold starts. Of course, using the premium plan will create a minimum infrastructure cost linked to your functions.
Improving the performance of your Azure functions
Understand the invocation context of functions
Before we can go into more detail on how to improve your function performance and the code running inside the functions, we need to make sure we understand the invocation context of a function. We need to understand which code of our function is only running once on startup and which code runs on each request handled by your function.
The following C# and NodeJS examples provide information about the invocation context:
// This code only runs at first startup of the function instance
private static HttpClient httpClient = new HttpClient();
public static async Task Run(string input)
{
//This code runs at each invocation/request
var response = await httpClient.GetAsync("https://example.com");
// Rest of function code
}
const { CosmosClient } = require('@azure/cosmos');
const { COSMOS_API_URL: endpoint, COSMOS_API_KEY: key } = process.env;
// This code only runs at first startup of the function instance
const client = new CosmosClient({ endpoint, key });
const container = client.database("MyDatabaseName").container("MyContainerName");
module.exports = async function (context) {
//This code runs at each invocation/request
const { resources: itemArray } = await container.items.readAll().fetchAll();
context.log(itemArray);
// Rest of function code
}
In the following sections, we will see that the above code follows the best practices and why it is crucial to place code blocks in the right place.
Reuse connections
An important factor in improving the performance of your functions is reusing connections. For example, you should create the database connection outside of the invocation context. After that, you should reuse the same connection over the different invocations of the function. Connection reuse is not limited to database connections. You should reuse all outgoing (HTTP) connections as much as possible.
As you can see in the code above, they define the database and HTTP client outside of the invocation context. Since this code is only executed on startup, connections are reused for the different invocations over the VM's lifetime in which the function is run. If you do not reuse these connections, you can run into unexpected delays. These delays are often due to port exhaustion on the underlying load balancer.
Your functions and function invocations do not have a public outbound IP address. Instead, the SNAT functionality of Azure Load Balancers is used to give the functions access to the public internet. The number of ports on the Azure Load Balancers is limited, and releasing ports can take more than 10 seconds. Therefore, reusing HTTP connections is crucial. You can find more details around SNAT here.
Cache data locally
To reduce external connections even further, it is a good idea to look for data that can be cached in your code. For example, if you have some code that generates JSON Web Tokens based on a certificate stored in Azure Key Vault. It is a good idea to retrieve this certificate once and store the certificate outside of the invocation context of the function. This way, the amount of external calls is reduced. However, with caching techniques, it is crucial to see what data is eligible to be cached and how fast this data would go stale.
Cold starts
Due to the underlying scaling mechanism, it is crucial to optimize the package size of your code and the startup time of your application code. The package size should be as small as possible to have the best performance. When starting a new function instance (VM), Azure will download your code package to the VM. For bigger packages, this will take longer. To reduce package size:
- Use the "Run from package" functionality. This way, the code is downloaded as a single zip file. This can, for example, result in significant improvements with Javascript functions, which have a lot of node modules.
- Use language specific tools to reduce the package size, for example, tree shaking Javascript applications.
The next thing we should optimize is the startup performance of our application code. Here we need to check whether the setup done by the function code on startup is the responsibility of the function code. One clear example of this is ensuring the existence of the database and its tables. It should not be the responsibility of the function to create database tables on the fly. Instead, the creation of these tables should be part of your CI/CD pipeline. For CosmosDB you have following methods to retrieve a database table instance in your code:
async getDatabase(): Promise<Database> {
if (!this.database) {
const databaseResponse: DatabaseResponse =
await this.cosmosDBClient.databases.createIfNotExists({id: "<database name>"});
this.database = databaseResponse.database
}
return this.database;
}
Whether the database already exists, this code will start a network connection with CosmosDB to check whether the database exists. This connection is unnecessary and, as stated before, not the function's responsibility. Instead, create the database using Terraform or Azure Resource Management templates and use the following code:
async getDatabase(): Promise<Database> {
if (!this.database) {
this.database = await this.cosmosDBClient.database("<database name>")
}
return this.database;
}
Keep your functions warm
Another way to improve the cold start time is to reduce the number of cold starts that occur. One way to do this is by calling your function every 5 to 10 minutes to ensure that Azure keeps at least one function instance running. When you choose to go this route, we advise you to combine this call to the function with a health check. This way, you cover both performance improvements and monitoring of your functions.
In this health check, it is essential to verify whether the connection with external systems like databases is working. This is needed to get a good idea of whether the service/function is running correctly. Furthermore, this ensures that all connections are being created by the health check, ensuring that actual user requests can reuse these connections.
To implement such a health check, you can use Azure Application Insights availability tests. You can create a basic URL ping test, which will make an HTTP call every 5 to 10 minutes, depending on what you prefer. These ping tests are quite basic but also free! You are only charged for alert rules and notifications if you enable these.
CosmosDB specific improvements
Configuring the CosmosDB client
When creating the CosmosDB client, you can provide a lot of configuration. Some of these will reduce the amount of network calls the SDK is executing. Based on your use case, you can, for example, disable endpoint discovery, which will prevent the SDK from making additional calls to CosmosDB to get all read and write locations. Instead, the SDK will use the endpoint you provided.
Endpoint discovery is essential if you have multiple locations configured to improve availability. However, if you only have a single location configured, you can disable this without consequence.
connectionPolicy: {
enableEndpointDiscovery: false
}
Use the latest version of the SDK (or newer versions) (3.9.2)
Using the newest SDK version is always a good idea. When investigating the performance of our functions, we saw that creating the CosmosDB client was taking a long time. After making the above changes to the connection policy, we were sure that the SDK was not making any external call when creating the CosmosDB client. We started drilling down into the SDK to see what caused the issue and found the following. In the previous SDK versions, the SDK was using the os-name package, which uses the windows-release package. We were able to pinpoint that this Azure SDK dependency was slow when running on windows-based functions. After some alignment with Azure support, they notified us that the 3.9.2 version is not using the windows-release package anymore. This version was released on the 16th of September, 1 day after notifying Azure support of this issue.
The differences observed in the performance can be seen on the following graph. It shows for each half hour, how long it takes on average to create the CosmosDB client. From the 29th of September at around 6:30 AM UTC, you can see that the duration falls from multiple seconds on average to a couple of milliseconds thanks to our changes.
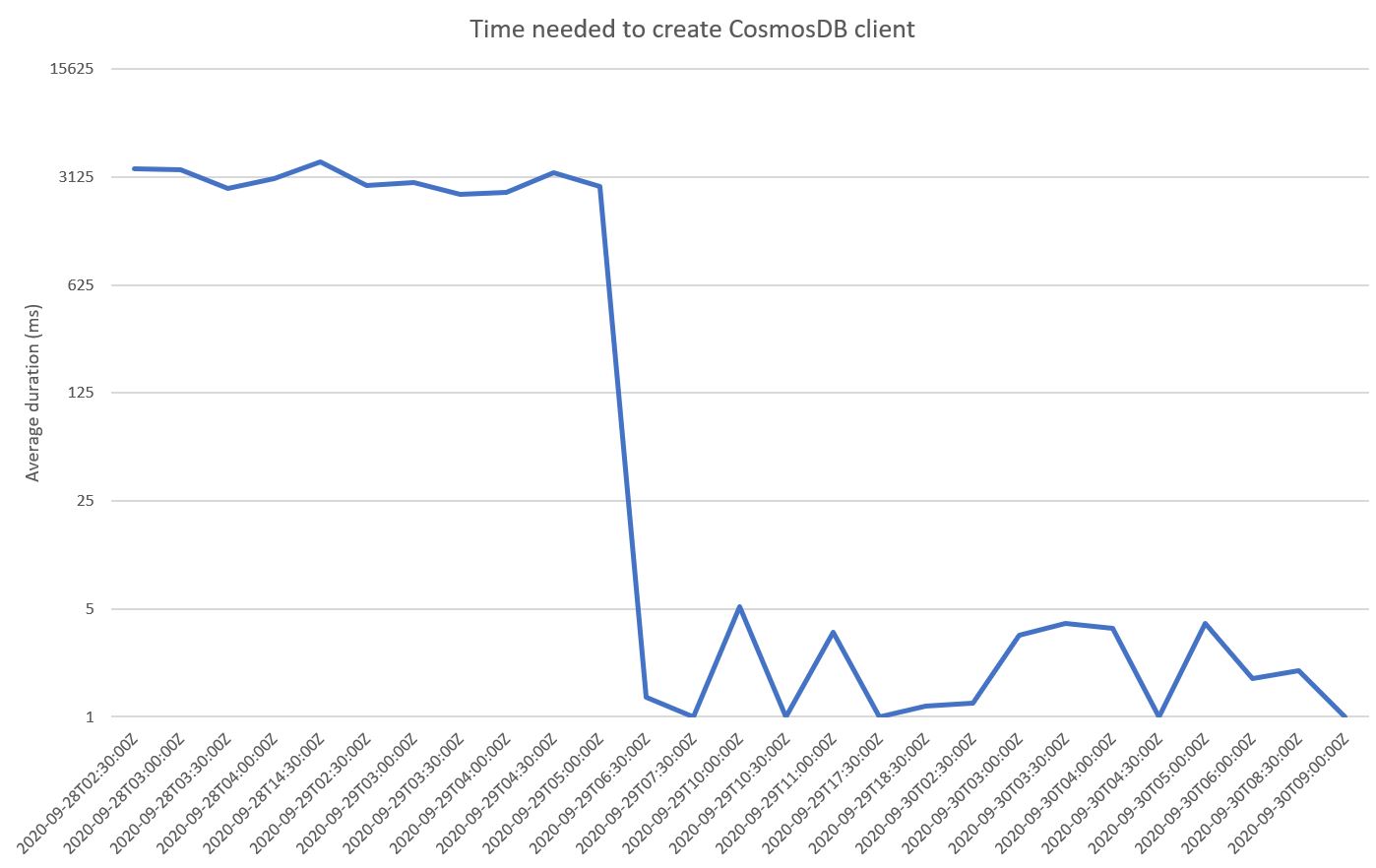
Before changing to the new version, we saw the following metrics for the CosmosDB client creation:
- Minimum: ~2 seconds
- Average: ~3.5 seconds
- Maximum: ~13.5 seconds
After turning to the new version, we saw the following improved metrics:
- Minimum: ~0.004 seconds
- Average: ~0.016 seconds
- Maximum: ~0.030 seconds
What's next?
I've tried to keep this blog as short and lightweight as possible. Of course, there is more to take into account when starting with Functions. We've covered: - What the invocation context of a function is - What cold starts are and how to mitigate the impact - How you can cache data locally in your functions - Best practices regarding connection reuse - How to improve the startup performance of CosmosDB
For more tips and tricks, you can read through the Functions best practices.
If you have additional questions regarding this blogpost, FaaS, or other Serverless services, please reach out to me on LinkedIn.


