Mitch Mommers
I'm Mitch Mommers, 22 years "old" and having the time of my life!
Follow: @stefceyssens

Part I: Background, results and the roadmap
You might have heard of it ... GraalVM, a polyglot virtual machine that's being developed by Oracle. But that's not what I'm interested in ... no, no! I'm interested in SubstrateVM which allows us to build native images of java byte-code and is a part of GraalVM.
Imagine a world where your Java code runs on its own, leaves a small memory footprint leaves that monstrosity of a JavaVM where it belongs (not on your system). This is it, you might think, finally free! But are we?
Almost? Maybe? I don't know?, is what comes to mind, but don't fear, I'm here to tell you about my journey. A journey of translating Indonesian sites, desperate attempts to get libraries to work and writing tools just to make my life (and yours) easier. This is my (three part) story on building a custom runtime imbedded in a lambda function thus making my AWS lambda run faster with only 1/4th of the memory needed in comparison to the JavaVM.
And I know you might have read similar articles before and there is this beautiful thing called Quarkus (among others). But there is a reason for writing this article and spending quite some time writing the code, that allows us to proof everything that you will read here. But, first things first ...
The Big Why?
Cloudway, is a start-up in Belgium that focusses on Cloud Native Development on public cloud providers (e.g., AWS, Azure & Google Cloud Platform, ...). We love to use the various services provided by them and specialize in writing software that runs purely in the cloud and aim to be as serverless as possible.
Most of our work is done in Java (and various projects in python and node.js). It depends on the customer and our partners. You might say we are flexible.
However, we (among others) experience problems with Java for server-less technologies. And especially with one of our favorite services AWS Lambda. One of them is cold-starts, another one is memory usage.
If you have never heard of a cold start, it’s the time required to start and setup a container that is able to run your code. This can take some time depending on environment and configuration options. And each container can process one consecutive request. However, the first request that comes in has to wait for the cold start to finish.
Java requires that big JavaVM to start and during cold starts this together with initializing your code, can take up to twenty seconds. There is also the memory that the JavaVM uses. Both add to the cost of using Java for your lambda. Compare this to a Node, Python or Go lambda and the conclusion would be Java is slow and costs me more.
There are solutions for these problems, but most of them avoid the actual issue (the JavaVM) and are more or less workarounds, like keeping a Lambda warm thus avoiding the cold starts but increasing the number of executions. But I wish to get rid of the JavaVM and that's why ...
Gramba
I started this project called Gramba (GraalVM + Lambda) to remove the JavaVM entirely from the execution stack. It consists of a runtime for AWS Lambda and some tooling (maven plugins) to make the setup easier.
But the main goal here is to have a drop-in runtime, which can easily be included and excluded from a lambda function. This approach allows us to be fully backwards compatible (obviously) and solves the two issues that we are having concerning memory usage and cold starts.
SubstrateVM uses ahead-of-time (AOT) compilation, which means that there are certain limitations, which can be found here. Some of these limitations have workarounds and I would like to discuss three of them.
Reflection
One of the big functionalities of Java and one that kind of revolutionized the way we write software is Reflection. Which is also a big hurdle for AOT compilation, as reflection is handled at runtime.
But without the JavaVM such a runtime, doesn't exist anymore! However, SubstratesVM native-image command allows you to supply a configuration file that tells Substrate which classes (and which methods/properties) have to be reflect-able.
This configuration file might look something like this:
[
{
"name": "java.util.LinkedHashMap",
"methods": [
{
"name": "<init>",
"parameterTypes": []
}
]
},
... <snip 1600 lines />
]
Which means, that we tell the AOT compiler that java.util.LinkedHashMap is to be available for reflection. Then we tell him that only the no-args constructor (<init>) should be exposed.
There are also wildcard options available such as:
{
"allDeclaredConstructors": true,
"allPublicConstructors": true,
"allDeclaredMethods": true,
"allPublicMethods": true,
"allDeclaredClasses": true,
"allPublicClasses": true,
}
They make your work a bit easier, by removing a lot of the fine-grained configuration.
But you can imagine, this will take a lot of time to set up. And you might not even know all the classes that are to be reflected. A missing entry results in errors and might even result in corrupted data or missing information.
Every file that is being reflected with or without a direct reference has to be in this configuration file. Which is some tedious and error prone configuration work to do. You could solve this by using some tooling that creates the reflection.json, or use the undocumented Feature interface, but more about this in the following blogpost.
Runtime class loading
Imagine you are using a library for instance the Apache HTTP Client, you think well let's create a native-image and suddenly the entire thing crashes because no logger could be found, and no default implementation could be created.
This is what happens when you use the AWS-SDK. Which uses (a variation of) the Apache HTTP Client for all of their API calls, and the fix in the code below wasn’t that bad but still it’s silly.
The creators of SubstrateVM don’t recommend you to use it, it’s well hidden and barely documented. And I don’t think they are wrong, maintainers should provide proper support and not the other way around.
But until then you have to do it yourself and your main class will have some additional static classes that look like this:
@TargetClass(org.apache.commons.logging.LogFactory.class)
final class Replace_Appache_Log_Factory_For_AWS_HTTP_CLIENT {
@Substitute
protected static Object createFactory(String factoryClass, ClassLoader classLoader) {
return new LogFactoryImpl();
}
}
@TargetClass(org.apache.commons.logging.LogFactory.class)
final class Replace_Apache_Log_Factory_getLog_Method_For_AWS_HTTP_CLIENT {
@Substitute
public static Log getLog(Class clazz) throws LogConfigurationException {
return new SimpleLog(clazz.getName());
}
@Substitute
public static Log getLog(String name) throws LogConfigurationException {
return new SimpleLog(name);
}
}
And yes, it is as it says, we are replacing a method to return a fixed logger, jeej! It's not great but it’s something that you have to do once and doesn't impact your program afterwards. The problem is, it has to be in your main file in order for SubstrateVM to find it and you lose some Java functionality (runtime class loading).
The bigger problem here is finding documentation. The native image concept is fairly new and when using libraries that aren't common, you might not find any information at all. This, off course, would solve itself over time, when more people hop aboard of the GraalVM ship and more and more libraries support native image compilation out of the box.
Static initialization
This is another tricky one, and also pretty commonly used. Imagine you have a class of constants and being a good person, you define them as follows:
public static final String KMS_ARN = System.getenv("KMS_ARN");
It's perfect, its final so we can't change it anymore, its static so for everyone the same but it’s not going to work if you expect KMS_ARN to be declared during runtime. Because it will now be set at compile time by our AOT. Which will interpret this, run it and make it fixed for our native image.
But my lambda isn't going to have the same KMS_ARN on every environment, and I'm not going to rebuild this between my dev and staging environments. What now?
We delay the class initialization to runtime by adding the following line to our native-image command:
--delay-class-initialization-to-runtime=be.cloudway.test.project.common.Constants
Which will ensure that our constants class, will be initialized at runtime and not at compile time.
This list of delayed classes is comma separated so you can supply a number of these classes using static initialization. Whether it is a static class, static initializer block, static properties, ... Once again, some hideous configuration, however often required.
Lastly, some libraries do some fancy stuff in static initializer blocks which makes them nearly, if not unusable. This can be troublesome if you depend on such a library.
And there are many more of these silly things, which aren't really documented in a central place. This is one of the things that we wish to address and help with.
So, in the next blog we will look more into practical examples on how to tackle these issues and supply you with some tooling to make life easier! This blogpost might seem like a teaser but at least now you know what you are getting yourself into (which is seldom the case), so let's have a look at ...
The benefits
You might think Yikes, I ain't gonna touch that. But don’t worry as I've shown you, they aren't that terrible to fix. But yes, they do cause for some trouble.
They might even turn you ~insane~ and especially when wanting to use this in production. For instance, AWS has a lot of exceptions that are mapped using reflection and for each of these exceptions that might occur, you now have to supply an entry in your reflection config file. If you miss one, you might get an exception for an exception. (And that's just wrong!)
So why go through all this burden and pain, well pain can be reduced with tooling teaser! and the payoff is still pretty big. Let’s start with …
The benchmark
It’s important to know that all results are run against precisely the same set up. Except for the lambda runtime and that Gramba uses a native-image and not the JavaVM.
To keep our results realistic, we choose to have a fully functioning application to test against. Authentication is done against AWS Cognito and we communicate with the Lambda over HTTPS using AWS API Gateway.
The sample is based on 400 requests (100 cold, 300 hot) for each runtime and memory setting.
Each timing starts when we send a HTTP request from our local system and stops when we get a response. This again to simulate a real-world scenario.
The endpoint that we use fetches job listings from a MySQL database. It uses, among other things, Dagger2 for dependency injection, the MariaDB J/Connector for the MySQL connection, QueryDSL and DataMapper for accessing the database and mapping the results, AWS Simple Email Service, AWS Secret Manager, AWS S3, JWT, Jackson, …
So now you know the setup, let’s get into the results.
Cold starts
Cold starts occur when your Lambda has been inactive for some time or is newly created and needs some time to spin up an instance to respond to the first request that comes in. There are many publications on this subject so I’m not going into detail but …
Let me show you the following graph (Fig 1.).
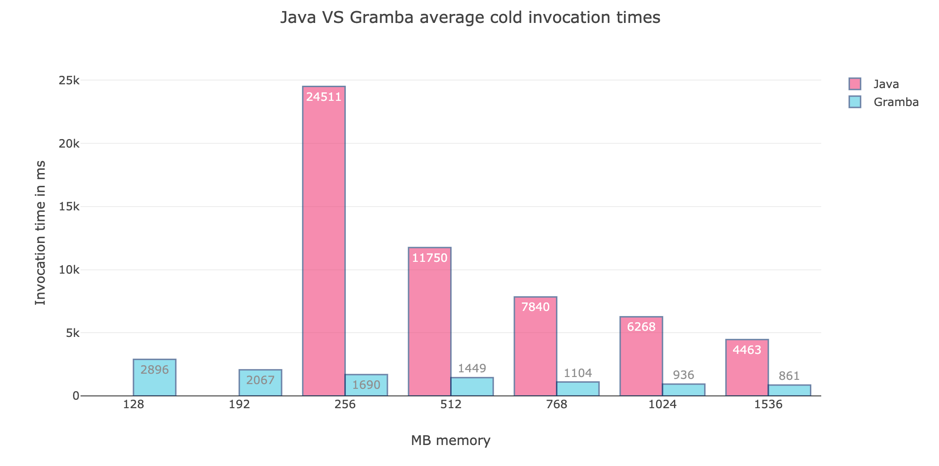
Fig 1. Graph displaying java and gramba cold invocations The graph shows cold start times average times, for a Java function running on AWS lambda and for a Gramba runtime native image lambda running the same function.
Glimpsing at the number you will notice somethings:
- Gramba at 128MB of memory is still 1.4 seconds faster than Java at 1536MB of memory.
- There are no tests at 128MB memory and 256MB memory for Java because it runs out of memory.
- Java at 256MB of memory is about 14 times slower than Gramba at 256MB of memory and about 10 times slower than Gramba at 128MB of memory.
These are some significant differences in start times, which is obvious considering that one is a native image and runs standalone and the other first starts a JavaVM to then just-in-time compile the code and run it.
But speed is not everything, so what about pricing?
Pricing
Now, AWS pricing is linear. It is calculated based on the run time rounded up to 100ms intervals and the configured memory usage. Hence, running a 128MB lambda is four times cheaper than running a 512MB lambda, if they run for the same duration.
And that’s why the following tables are significant. Just look at Fig. 2 you will notice that Gramba also has lower execution times for hot starts. Which means it’s cheaper than the same code as a Java lambda.
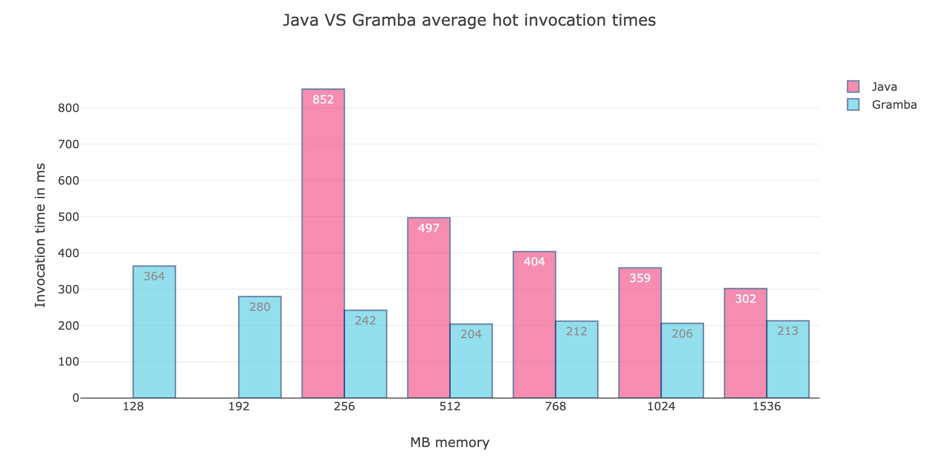
Now to give you a better understanding of the AWS Lambda Pricing here are some calculations for AWS Lambda compute costs.
- If we pick the Java Hot at 512MB with its average speed and 100 million invocations, we pay: 416 dollars
- If we pick Gramba Hot at 512MB its average speed and 100 million invocations, we pay: 250 dollars
- If we pick Gramba Hot at 192MB its average speed and 100 million invocations, we pay: 93 dollars
Gramba Hot at 192MB is the most efficient choice for Gramba however 128MB would only cost 83 dollars.
If you are wondering why we compare a 192MB Gramba Lambda against a 512MB Java lambda. It’s because they are the closest in average execution speed at still reasonable memory usage. And thus it’s logical to calculate the price difference for reasonable settings.
Now, to show you the cost benefits for one of our clients that relies heavily on lambdas. We did a cost analyzes for a part of the project using Java.
The project uses AWS Lambda together with AWS Step Functions for data enrichment. Great services that work really well together. However, we were required to develop the lambdas for the step functions in Java. Each successful execution of the step function flow would trigger ten lambda executions.
Our client expects that this Step Function flow will be executed about 400 000 times a day. On a monthly basis this would get us 120 000 000 lambda invocations.
To remind you, for AWS Lambda you pay for the amount of RAM reserved multiplied by each 100 milliseconds your function runs. The Lambda functions in this scenario do some complicated math, and for the initial pricing we took 5000ms of runtime and RAM has been set to 1024MB.
This results in the following (worst case) scenario:
((RuntimeInMs / 100) * PriceForRamReserved) * Invocations
= ((5000 / 100) * 0,000001667) * 120 000 000
= (50 * 0,000001667) * 120 000 000
= 0,00008335 * 120 000 000
= 10 002
Which means that for our current setup we pay about 10k dollars a month. But with Gramba we expect to be able to run at least with half the memory. Paying only half of the current monthly price. And this might even be less because of slightly reduced execution time.
If the client agrees we might actually deploy this in a pre-production environment because step functions are a more controlled environment in which we can cover and workaround most issues that SubstrateVM has. When this happens, we will happily write about it in a blogpost!
And one might still ask: “why not use Node, Go or Python?”. The answer is simple: the requirements do not always allow us to. So, this might be a good way of still using Java but mitigating the drawbacks of JVM in lambda. And we know that comparing Java against a Binary executable is an unfair fight. But it works and given some time it could make a substantial difference in the service we offer our clients.
The Roadmap
Sadly enough, it is not yet production ready. However, we are dedicated to make it work. Once we are confident enough to run it in production, we will ensure you can do the same.
It does however require some dedication, hence, in future blog posts we will try to tackle the following issues:
- Centralise and open-source the configuration requirements for external libraries. So that other people can find them and contribute. But also, to make these libraries aware of the required configuration (and if possible, to fix these issues);
- Open-source our tooling and runtime, so that everyone can enjoy Gramba;
- Provide configuration as drop-in modules with versioning;
- Provide a real-life example;
- Provide CI/CD examples;
- Provide a platform for testing Gramba with external libraries.
We hope by doing this we can ease the transformation from the JavaVM to native images in the AWS Lambda world, to win some production trust for GraalVM and to make Java a more valid option for lambda development. Because with native images, Java programs will run faster and be less expensive.
SubstrateVM and GraalVM are projects that we support and trust. They have great goals and plans, and if we can help a little, we are happy to do so.
That's it and while you are reading this, I'm at work, preparing some open-source releases and corresponding blog posts to help you on the way.